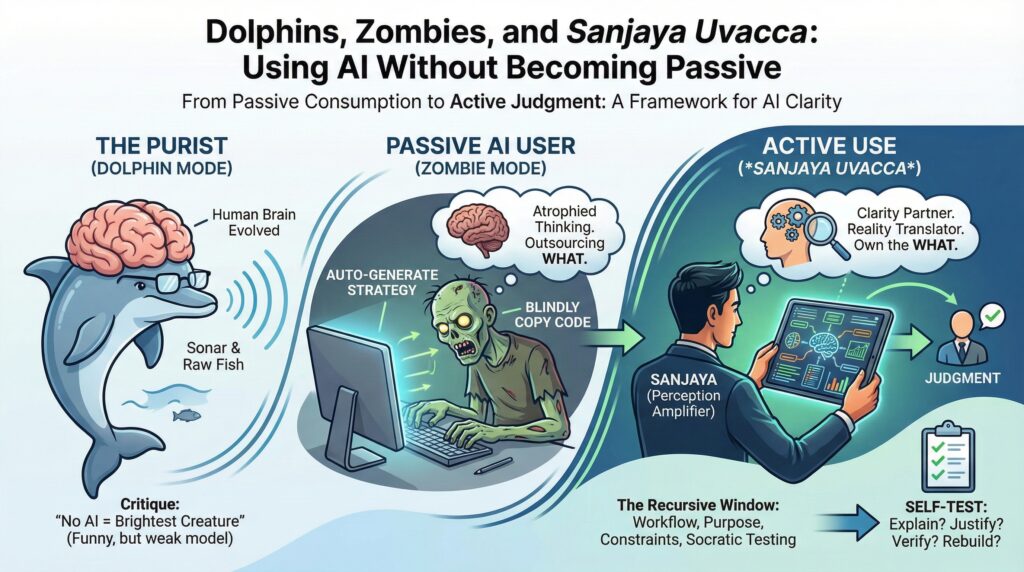
Dolphins, Zombies, and Sanjaya Uvacca: Using AI Without Becoming Passive
When people are substituting mankind with machinekind, there are certain collateral damage happens. It is quite normal, luddites of AI era, have been on the rise. Here what is being claimed, the changes in the structure of brain. New anatomical evidence reveals the shocking difference between AI users and AI purists. According to a rigorous scientific diagram, if you strictly refuse to use LLMs, your brain doesn’t merely remain human. It evolves into a massive, highly complex organ capable of sonar and eating raw fish. You basically become a bottlenose dolphin. 🐬 Some critics kind of imply: “Those who don’t use AI are dolphins: the brightest and smartest creatures swimming among us ChatGPT zombies.” Funny line. Weak model. Because the real dividing line isn’t AI vs no AI. It’s passive use vs active use. Let me show you the anatomy of the Nueral Machine ( Machine Brain). And Credits: Graphcore. Apply for 500+ Semiconductor jobs in Graphcore, Bangalore. Graphcore, now a wholly owned subsidiary of SoftBank Group, will invest up to £1 billion over a decade to establish an AI Engineering Campus in Bengaluru. The plan targets ~500 semiconductor jobs, with ~100 roles hired immediately across silicon logic/physical design, verification, characterization, and bring-up. The expansion in India is paired with a UK headcount increase to ~750, primarily in silicon, software, and AI engineering. The campus will contribute to Graphcore’s end-to-end AI compute stack (silicon, systems, software). SoftBank’s broader AI push includes large-scale infrastructure initiatives such as Stargate, in partnership with OpenAI and Oracle. SoftBank reports >$12 billion invested in India over the past decade. Rationale (explicitly stated): Bengaluru’s concentration of universities, startups, and multinational tech talent. Alignment with Indian government semiconductor initiatives and skills development. Implications (inference, bounded): Signals deepening global semiconductor R&D presence in India, not just services. Positions Graphcore to scale AI silicon development capacity while diversifying talent geography. Reinforces SoftBank’s strategy to vertically integrate AI infrastructure—from chips to platforms. Bottom line: This is a long-horizon R&D and talent bet, anchoring advanced semiconductor engineering in India while integrating Graphcore into SoftBank’s broader AI infrastructure agenda. Career at Graphcore Director / Senior Principal AI SoC Validation (Bring-up lead)Engineering – SiliconApply now Principal Bring-Up and Characterisation EngineerEngineering – SiliconApply now Principal Embedded SW/FW Engineer (Bringup) – Bengaluru, multiple vacanciesEngineering – SiliconApply now Principal Silicon Physical Design Engineer – BengaluruEngineering – SiliconApply now Principal Silicon Verification Engineer – BengaluruEngineering – SiliconApply now Senior Bring-Up and Characterisation Engineer – BengaluruEngineering – SiliconApply now Senior Bring-Up and Characterisation Engineer – Bengaluru, Multiple VacanciesEngineering – SiliconApply now Senior Bring-Up and Characterisation Engineer – Bengaluru, Multiple VacanciesEngineering – SiliconApply now Senior Embedded SW/FW Engineer (Bringup) – Bengaluru, multiple vacanciesEngineering – SiliconApply now Senior Embedded SW/FW Engineer (Bringup), Bengaluru, multiple vacanciesEngineering – SiliconApply now Senior Silicon Physical Design Engineer – BengaluruEngineering – SiliconApply now Senior Silicon Verification EngineerEngineering – SiliconApply now Silicon Physical Design Engineer – Bengaluru, Multiple VacanciesEngineering – SiliconApply now Staff Bring-Up and Characterisation EngineerEngineering – SiliconApply now Staff Bring-Up and Characterisation Engineer – BengaluruEngineering – SiliconApply now Staff Embedded SW/FW Engineer (Bringup) – BengaluruEngineering – SiliconApply now Staff Silicon Logical Design Engineer – Bengaluru, Multiple VacanciesEngineering – SiliconApply now Staff Silicon Physical Design Engineer – BengaluruEngineering – SiliconApply now Staff Silicon Verification Engineer – Bengaluru, Multiple VacanciesEngineering – SiliconApply now The Connotation We’re Beating: “Using AI Makes You Passive” There’s truth inside the fear. If you stop exercising a muscle, it atrophies. If you use AI to replace thinking, you’ll get worse at thinking. That’s what “getting dumber” looks like in practice: blindly copy-pasting code you can’t explain, auto-generating strategy you can’t defend, letting autocomplete decide your business logic, accepting output without checking assumptions. But here’s the distinction people keep skipping: Outsourcing thought and outsourcing execution are two different things. AI can accelerate the HOW—drafting, refactoring, summarizing, exploring options. Humans must own the WHAT—what matters, what to build, what tradeoffs to accept, what “good” looks like, what you’re willing to be accountable for. Passive consumption makes you dumber. Active use makes you sharper. So how do you force active use every time? That’s where Sanjaya Uvacca comes in. Sanjaya Uvacca: Not “Just a Narrator,” But a Discipline of Clarity “Sanjaya uvāca” literally reads as “Sanjaya said…”—and it’s easy to treat that like a speaker label you skip past. But Sanjaya isn’t a decorative narrator. He’s an archetype: the lucid witness who can stand near chaos without being swallowed by it, and transmit what matters without distortion. And that gives us the cleanest metaphor for using AI well: In the Mahabharata, Sanjaya is the bridge between battle and blindness: he translates an overwhelming battlefield into clear perception for someone who cannot see it directly—without taking the choice away from him. That’s the most accurate metaphor for Artificial Intelligence. Our “battle” is complexity (information overload, shifting contexts, endless variables). Our “blindness” is cognitive (limited attention, limited time, partial knowledge). Used well, AI becomes a Sanjaya: it expands perception—summarizes, compares, surfaces risks, reveals tradeoffs—so the human can answer the harder question of what matters and what to do. Used poorly, AI stops being a bridge and becomes a crutch: it doesn’t cure blindness, it replaces judgment. So the goal is not “use AI” or “don’t use AI.” The goal is: use AI like Sanjaya. Perception amplifier. Clarity partner. Reality translator. Not a substitute decision-maker. The Recursive Window: Features That Make Passive Use Hard I don’t rely on a “magic prompt.” I rely on a workflow—a recursive window that forces thinking before output. Here are the features: 1) Start with purpose and constraints Before generating anything, the process forces you to define: what outcome you want, who it’s for, what constraints matter (time, budget, risk, tone, scope). This immediately locks you into the human job: WHAT are we trying to do? 2) Build a map before building the artifact Instead of jumping to a final answer, you first create structure: a syllabus for learning, a plan for execution, dependencies and “unknowns” made visible. This prevents the
